

…or you could just not use AI.
Genuine question, but what do people actually use LLMs for? I’ve installed Ollama and tried to use it to generate some alt text with some Gemini thing, but what I got out ranged from meh to mostly unusable.
Well today somebody tried to use it in a job interview I was conducting.
What, live during the interview? Jeez…
I’ve interviewed a few people and I get them to tell me a story about something from their job history … if they’re reading stuff off the screen it’s then really obvious for a looooong time
I’m a web Dev and I use LLMs a lot, one of the best uses I’ve found is to make small tools, for example, I have a tool where I can specify a name and a list of variables, and it will output a stored proc template with my preferences, and some code that I can use in my chosen language to call the proc.
If I need to use a code library for a single task but it’s 3rd party and I’m not going to use it again, I’ll get an LLM to write me some examples so I can understand how to call the thing, saves me a lot of brain power.
I also use it to write me functions that I don’t have available but I know have been written a million times before, like an LPAD function.
I’m also using it for music recommendations, new version of chat can search the web and amalgamate multiple sources like Reddit, last.fm and give me a neat little report on bands I might like to listen to based off artists I give it, I’m currently using it to explore psychedelic music from places like Turkey.
I also used ChatGPT recently to generate me 2 images of a guy to get around discords age check so I didn’t have to give them my actual face.
I did try and get it to help me write a dating profile but everyone could tell it was LLM written so I binned it.
They are actually really good in translating texts or improving writing if needed.
Improved writing for your Corporate Newsletter
I use it to fix my grammar when I have to write something official at work.
I use it a couple times a month for AutoCAD LISP routines because, unfortunately, Lee Mac doesn’t work for us.
Chatgpt has made me a dozen or so routines that condense 1-10 minute tasks into 5 second. I use at least a few of them every single day.
The actual answer:
Deepseek running local. You don’t have to give ANY data away.
Doesn’t DeepSeek still censor sensitive questions (e.g. about Taiwan and the Tiananmen protests) when ran locally and offline?
Although it’s certainly got its merits (being FOSS? and much more energy-efficient than most models), censorship of state violence is still bad.
I wonder how other chat AIs do, concerning that censorship. Grok we already know to be shit, it warps the truth beyond words. Even regarding non-political stuff, its accuracy is trash compared to other models.
How about ChatGPT? Ollama? Kobold? Llamafile? Do they censor stuff?
Every model has bias due to its training set. And each model has strengths and weaknesses based on various factors including their training sets. The real correct answer is run an ensemble of local models and use the best one for any given task.
Its not Foss its open weights there is a huge difference
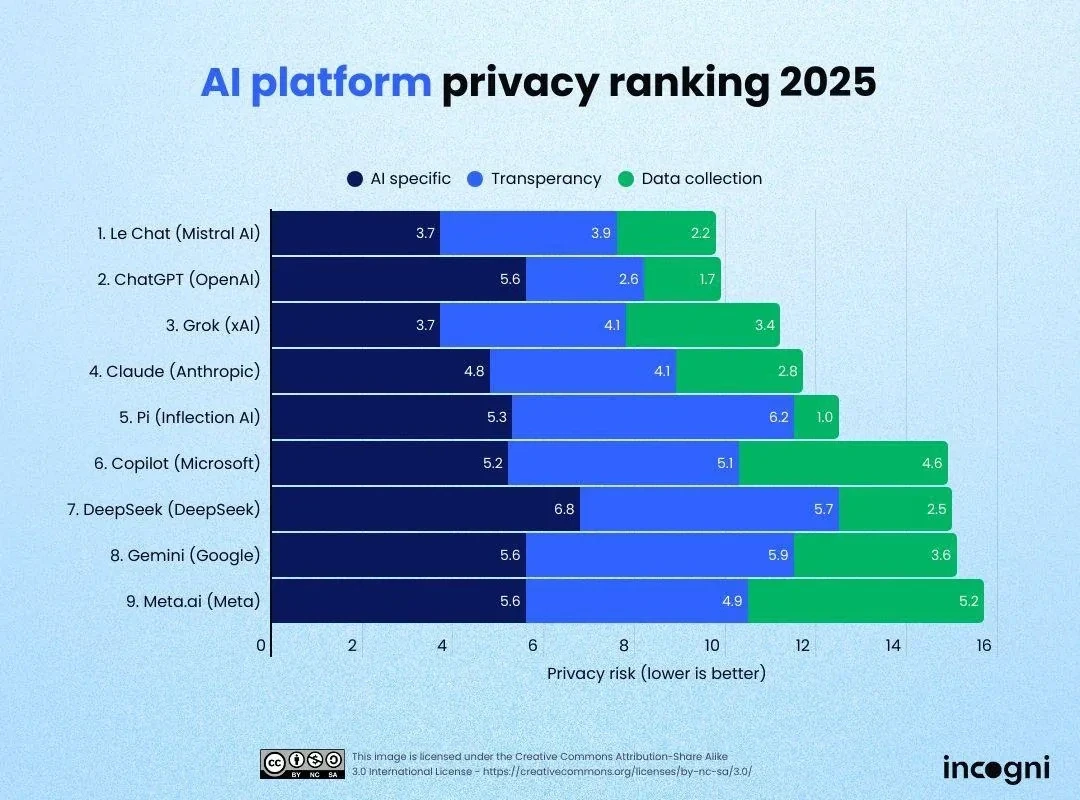
What does the “transperancy” correspond to? It doesn’t look like a data collection thing.
I expect it to be about how much is made public about what’s ‘under the hood’ so to say. Maybe only about how the AI works or where data is stored, but could also be about how much energy is used, what hardware it runs on or what data it’s trained on.
Oh good they scored 2.2 privacy units in privacy. How informative. This isn’t a graph this is just some coloured rectangles with arbitrary text printed on them.
What measuring scale is this in, is it a recognised SI unit?
The public dataset with details about criteria and findings can be found here: public data.
And Ollama then? Kobold.cpp? Llamafile? Those might arguably be better.
Those are neither companies nor models
deleted by creator
GP’s list contains products/services. I believe they are asking how do self hosted products compare. Also ollama is transitioning to a paid product and likely have privacy questionable functionality embedded in newer versions. It would be good to compare these available options as well.
What do the scored categories actually mean? How were they scored? How was the data sourced?
Disappointed to see this image getting upvotes as-is. Without proper context, it’s barely a step above a Facebook boomer meme in terms of credibility.
You can find more information here: https://blog.incogni.com/ai-llm-privacy-ranking-2025/
Meh. It might be better than the others in terms of privacy, but that doesn’t mean it’s really private.
The most private solution is to self host it or not use it at all.
Should I understand this image as Incogni writing down their vibes for each company?
I use Protons Lumo from time to time, havent figured out in which cases it performs better or worse compared to mistrals LeChat but i expect they would rank high if they were part of this research. Do think ChatGPT remains superior in many other ways, unfortunately.
I second that. Lumo is private. Quality is not gpt, but Mistral is kind of shit too and I don’t like their ui.
My plan was to make my own private one, now with lumo I don’t know. I’d still like to tinker with it, but maybe later. An option is also Venice AI that’s anonymous and pretty good, it’s crypto though.
deleted by creator
I believe Lumo uses Mistral and some other models combined under the hood
ChatGPT has much lower data collection?
@Sunshine@piefed.ca This list is missing many names: to mention some of the platforms I know, there are also Qwen, QLM and Kimi (Chinese), Maritaca Sabiá IA and Amazônia IA (Brazil). There are also smaller (often homebrewed by hobbyists) language models (SMLs) often found on HuggingFace.
Online platforms aside, self-hosted (offline) inference is the most private way to run LLMs, independent of who built it (be it Llama from Meta, Gemma from Google, Mixtral, DeepSeek or Qwen: they can’t really collect data from offline usage, especially if one proceeded to fully air-gap their computer).
lmao using ai
Transperancy
I’m guessing the scale is out of 10
Why guess if there’s a labelled axis that goes to 16?
Perhaps they mean the scale of the three individual topics.
Well 16/16 privacy risk doesn’t seem high enough for Meta, and is a weird number to use. There is nothing here to indicate that the scale ends at 16, hence the guess. But 16/10 seems like the right ballpark for Meta’s privacy risk.









{kind=link}